
티스토리 뷰
빅쿼리를 사용하게 되면 로컬 또는 GCS에 업로드된 CSV 파일을 테이블로 로드하는 경우가 있다.
최근에 이러한 작업을 많이 하게되어 자주 사용한 명령어들에 대해서 정리를 해보았다.
gsutil
gsutil은 명령줄에서 Cloud Storage에 액세스하는 데 사용할 수 있는 Python 애플리케이션이다.
gsutil을 사용하면 콘솔에서 직접 조작하는 것보다 간단하고 다양한 기능들을 수행할 수 있다.
gsutil cp
로컬의 파일을 전송하거나 gcs에 있는 파일을 다운로드한다.
gsuitl cp [source] [dest]
- 로컬에 있는 파일을 gcs의 test-hyunlang이라는 버킷으로 업로드 하였다. 다운로드 할때는 위치를 바꿔서
[source]쪽에 gcs 경로를 위치하고[dest]쪽에 다운로드 받을 경로를 지정해주면 된다.
gsutil -m
gsutil -m cp file gs://bucket다수의 파일을 업로드하는 경우 m 옵션을 사용하면 병렬적으로 작업이 수행되어 수행속도가 빠르다. 나는 주로 cp에 사용했지만 지원되는 작업(acl ch, acl set, cp, mv, rm, rsync, setmeta)에 모두 적용된다.
gsutil cat
업로드가 잘 되었는지, 파일의 내용이 잘 들어갔는지 확인해보고 싶은 경우가 있다. 이럴때는 로컬에서와 동일하게 cat 명령어를 통해 내용을 바로 확인할 수 있다.
gsutil cat gs://bucket/path
cat으로 특정 라인 보기
파일에서 빅쿼리 테이블로 업로드를 할때 Error while reading data, error message: Missing close quote character (").; line_number: 12345와 같은 에러가 발생하는 경우가 있다. 파일이 작으면 금방 다운로드하고 업로드 하겠지만 파일이 큰 경우에는 시간이 다운로드 받는데에도 시간이 꽤나 소요된다. 따라서 올라간 파일에서 문제가 되는 라인을 cat, sed를 통해 바로 확인할 수 있다.
gsutil cat gs://[bucket]/[path] | sed -n [line]pn: 모든 라인이 프린트 되지 않도록 한다.p: line에 대한 output이 프린트 되도록 한다.
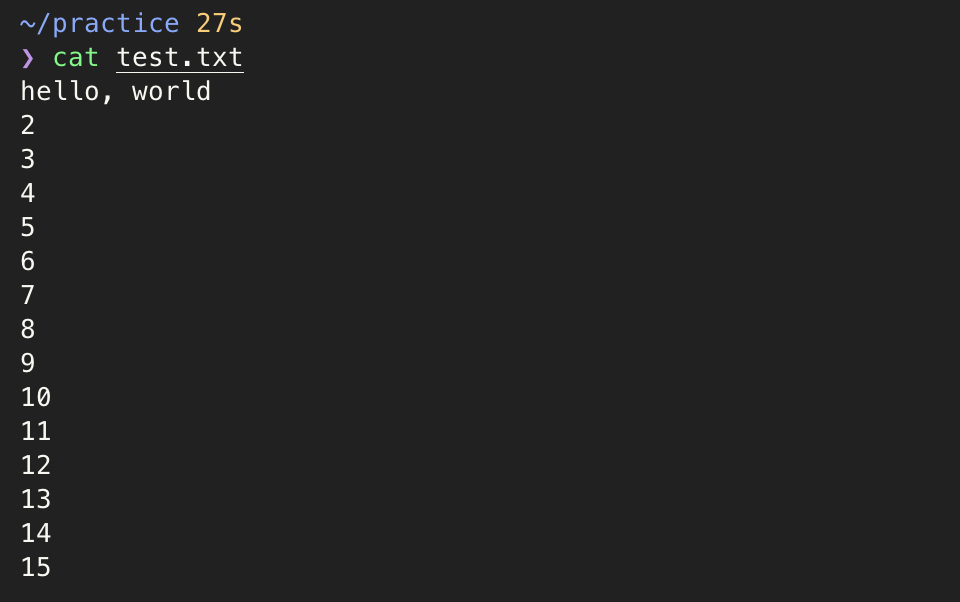
예를 들어 아래와 위와 같은 파일을 예시로 올렸다고 할때, 10번 라인에서 에러가 발생했다고 나온다면 아래처럼 확인이 가능하다. 개인적으로 매우 유용하게 느꼈던 명령어이다!

bq
bq는 빅쿼리를 위한 파이썬 기반의 커맨드라인 툴이다.
bq show
파일을 빅쿼리 테이블로 로드할 때 기존에 올라간 테이블의 스키마를 그대로 사용해야하는 경우가 있다. 이럴때는 스키마 파일을 만들어줘야하는데, bq show를 사용하면 기존 테이블의 스키마를 그대로 가져올 수 있다. --schema를 지정해주지 않으면 다른 정보들도 포함되니 주의하자.
bq show \
--schema \
--format=prettyjson \
{PROJECT_ID}:{DATASET}.{TABLE_ID} > {SCHEMA_FILE}.jsonoutput은 다음과 같이 생성된다.
[
{
"mode": "NULLABLE",
"name": "id",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "created_at",
"type": "TIMESTAMP"
},
{
"mode": "NULLABLE",
"name": "modified_at",
"type": "TIMESTAMP"
}
]bq load
CSV 파일을 빅쿼리 테이블로 로드할때 가장 많이 사용하는 커맨드의 형태이다.
bq load --schema={SCHEMA_FILE} --source_format=CSV \
{PROJECT_ID}:{DATASET}.{TABLE_ID} \
"gs://{BUCKET}/{CSV_FILE}"여기서 지정된 스키마가 없고, 일단 테이블을 확인하려고 한다면 --schema대신 --autodetect를 사용한다.
*을 사용하여 복수의 파일을 로드할 수도 있다. (ex. gs://{BUCKET}/*.csv.gz)
단, 로컬에 있는 파일에 대해서는 와일드 카드를 사용한 일괄 로드를 지원하지 않는다는 제약사항이 있으므로 참고하자.(공식문서)
로컬 데이터 소스에서 데이터 로드 시 다음과 같은 제한사항이 적용됩니다.
로컬 데이터 소스에서 파일 로드 시 와일드 카드와 쉼표로 구분된 목록이 지원되지 않습니다. 파일을 개별적으로 로드해야 합니다.
추가 flags
추가적인 flag들은 데이터의 형태에 따라서 다양하게 추가된다. 이 중에서 사용해본 적이 있는 flag들만 설명해보겠다.
--force={true|false}- bq load 작업에서 생성되는 테이블이 이미 존재한다면 replace 할 것인지. 기본 값은
false이다.
- bq load 작업에서 생성되는 테이블이 이미 존재한다면 replace 할 것인지. 기본 값은
--allow_jagged_rows={true|false}- 기본 값은 false이며, csv 파일에서 optional 컬럼에 대한 값이 없어 행이 불균일한 경우 true로 설정한다.
- 행이 불균형한 데이터들을 로드하려고 하면
column position 33, but line contains only 32 columns.이렇게 컬럼 수가 맞지 않는다는 에러가 발생한다.
--allow_quoted_newlines={true|false}- 만약
"빅쿼리"라는 하나의 컬럼에 해당하는 값이"빅 쿼리"처럼 안에 줄바꿈이 들어간 경우 값을 따옴표로 묶고 그 안에 줄바꿈이 있다면 제대로 파싱할 수 있도록 true로 설정한다. 기본값은 false로 설정되어 있다.
- 만약
--field_delimiter=DELIMITER or -F=DELIMITER- csv 파일의 구분자를 설정한다. 보통
,(default 값)이 구분자이지만 다른 구분자를 사용하는 경우 이 옵션으로 구분자를 설정한다.
- csv 파일의 구분자를 설정한다. 보통
--max_bad_records=MAX- 테이블 업로드를 실패하는 경우
error message: CSV processing encountered too many errors, giving up. Rows: 12345; errors: 100; max bad: 0; error percent: 0max bad값을 확인할 수 있는데 기본 값은 0으로 설정되어 있으며 설정값보다 bad records가 많은 경우 에러가 발생한다.
- 테이블 업로드를 실패하는 경우
--skip_leading_rows=NUMBER_OF_ROWS- 파일의 시작부터 몇개의 rows를 제외할 것인지 설정한다. 기본 값은 0이며 보통 파일에 헤더가 포함된 경우
--skip_leading_rows=1로 설정한다.
- 파일의 시작부터 몇개의 rows를 제외할 것인지 설정한다. 기본 값은 0이며 보통 파일에 헤더가 포함된 경우
참고
'GCP' 카테고리의 다른 글
| bq CLI - bq load로 csv 업로드 (0) | 2022.08.21 |
|---|